

[Study-1주차] PetClinicProject 기능 명세 + 개념 정리 + 2주차 과제
[Study-1주차] PetClinicProject 기능 명세 + 개념 정리 + 2주차 과제
[Study-0주차] Study 진행 방식 [Study-0주차] Study 진행 방식 https://github.com/spring-projects/spring-petclinic GitHub - spring-projects/spring-petclinic: A sample Spring-based application A sample Spring-based application. Contribute to spring
soohykeee.tistory.com
2주차 과제는 다음과 같다.
Pet-Clinic Project의 ERD를 보고, 모든 클래스 생성 + 의존성 주입만, 기능 개발은 X
각 본인 Github - Repository에 '초성 + PetClinic-Study' Project 생성 후 개발하도록 했다.
개발환경은 다음과 같다.
- Java 17
- Springboot 3.0.4
- Gradle
- IntelliJ
- H2
위의 과제를 위해 'jsh-PetClinic-Study' project 생성 후, github에 연동해주었다.
build.gradle, application.yml 파일은 다음과 같다.
plugins {
id 'java'
id 'org.springframework.boot' version '3.0.4'
id 'io.spring.dependency-management' version '1.1.0'
}
group = 'kr.co'
version = '0.0.1-SNAPSHOT'
sourceCompatibility = '17'
configurations {
compileOnly {
extendsFrom annotationProcessor
}
}
repositories {
mavenCentral()
}
dependencies {
developmentOnly 'org.springframework.boot:spring-boot-devtools'
implementation 'org.springframework.boot:spring-boot-starter-web'
// JPA
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
// Validation
implementation 'org.springframework.boot:spring-boot-starter-validation'
// DB
runtimeOnly 'com.h2database:h2'
// Lombok
compileOnly 'org.projectlombok:lombok'
annotationProcessor 'org.projectlombok:lombok'
//Test
testImplementation 'org.springframework.boot:spring-boot-starter-test'
}
tasks.named('test') {
useJUnitPlatform()
}
server:
port: 8080
servlet:
context-path: /
encoding:
charset: UTF-8
enabled: true
force: true
spring:
datasource:
driver-class-name: org.h2.Driver
url: jdbc:h2:tcp://localhost/~/jsh-petclinic-study
username: sa
password:
jpa:
properties:
hibernate:
format_sql: true
hibernate:
ddl-auto: create #create update none
naming:
physical-strategy: org.hibernate.boot.model.naming.PhysicalNamingStrategyStandardImpl
show-sql: true
패키지 구조는 다음과 같다.
전체적인 코드의 설명을 하기 전, 테이블 설계부터 살펴보겠다.
앞서 1주차에 설명했지만, 우리는 기존의 Pet-Clinic 프로젝트와 다른 점이 존재한다. Specialties 클래스와 Types 클래스를 enum 클래스로 생성하는 것이다. 우선적으로 우린 프로젝트가 중심이 되는 Study가 아니기에, 사용한 코드의 설명과 원리, 이유를 설명하기 위해 비교적 간단하게 테이블 구조를 아래와 같이 재설계 했다.
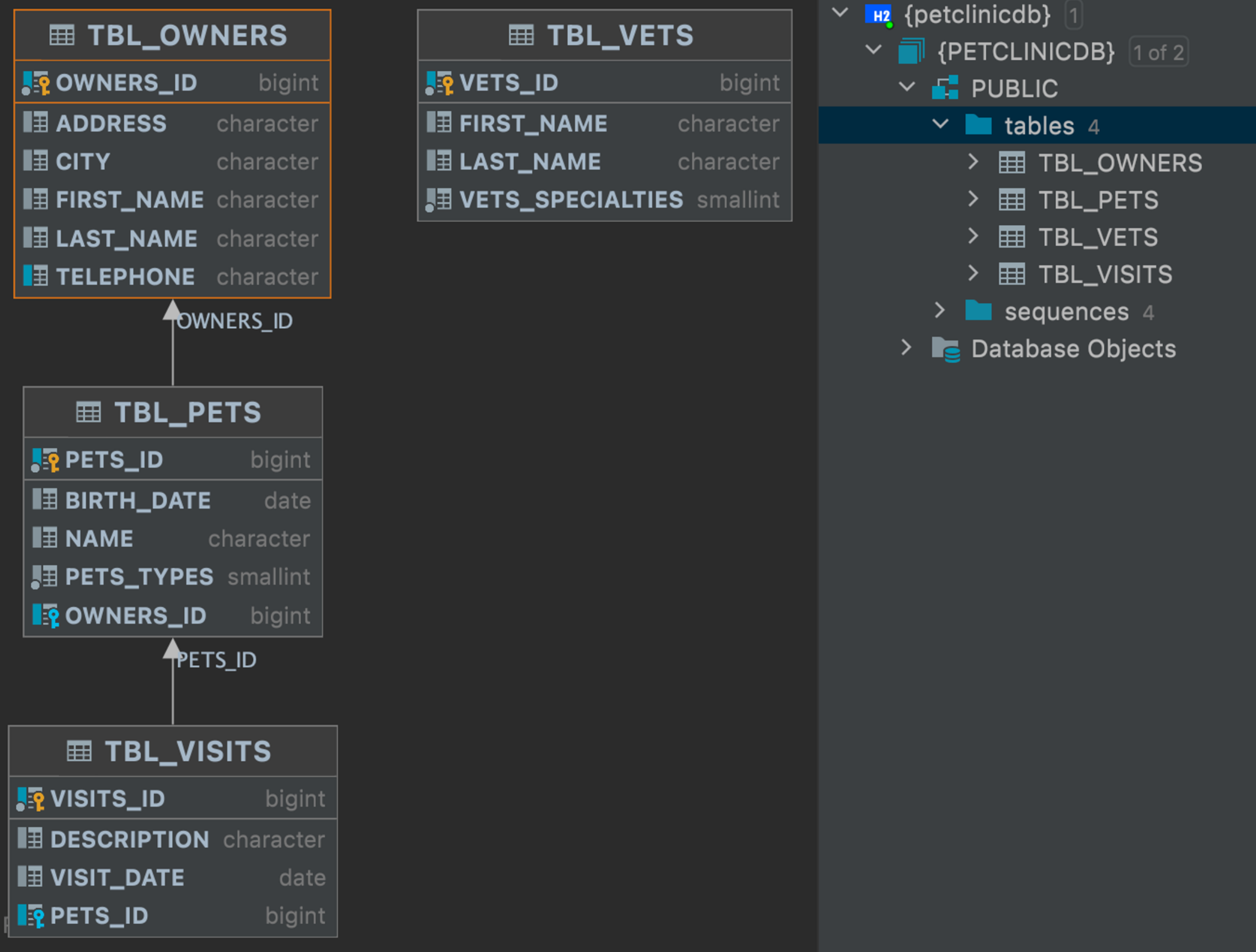
위의 테이블에서 보면, 모든 테이블들이 ID 값을 가지고 있다. 해당 부분은 BaseEntity로 분리해주어 관리해줄 것이다. 또한 기본적으로 BaseEntity를 사용하면 regDate, modDate와 같은 생성일자, 수정일자에 대한 정보도 공통으로 분리해주지만, 아직 해당 기능을 사용하지 않을 것 같기에 제외해준 후 BaseEntity에 생성해줄 것이다.
BaseEntity
package kr.co.jshpetclinicstudy.persistence.entity;
import jakarta.persistence.GeneratedValue;
import jakarta.persistence.GenerationType;
import jakarta.persistence.Id;
import jakarta.persistence.MappedSuperclass;
@MappedSuperclass
public abstract class BaseEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
}
@MappedSuperclass
- 부모 클래스를 상속받는 자식 클래스에 메핑 정보만 제공하며, 속성을 같이 쓰고 싶을 때 적용한다.
- 위에서 설명했듯이 모든 테이블에서 공통적으로 id 값을 사용한다.
그렇기에 BaseEntity인 공통 매핑으로 분리해주었다. - @MappedSuperclass 어노테이션이 부여된 클래스의 경우, Entity가 아니므로 EntityManager를 통해 조회, 검색이 불가능하다.
-> 조회 검색이 안되고 테이블과 매핑되는 칼럼도 아니기에 직접 사용 X, 따라서 추상 클래스로 선언을 권장
@GeneratedValue
- 해당 어노테이션을 사용하면, 식별자로 사용할 PK 값을 일일히 수동으로 넣어주지 않아도 된다.
- GenerationType.AUTO / GenerationType.IDENTITY / GenerationType.SEQUENCE / GenerationType.TABLE
- GenerationType.AUTO
: 적용한 DB의 방언에 따라 자동으로 설정된다. 해당 타입이 default 값이다. - GenerationType.IDENTITY
: 기본 키 생성을 DB에 위임하는 방식으로, id 값을 따로 할당하지 않아도 DB가 자동으로 AUTO_INCREMENT하여 기본키를 생성한다. - GenerationType.SEQUENCE
: 기본 키 생성을 DB의 Sequence Object를 사용하여 자동으로 생성, 해당 기능은 Oracle DB에서만 사용이 가능하다. + @SequenceGenerator 어노테이션도 추가적으로 필요하다. - GenerationType.TABLE
: 키를 생성하는 테이블을 사용하는 방법으로 Sequence와 유사, 모든 DB에 적용이 가능하지만 성능이 좋지 않음, + @TableGenerator 어노테이션도 추가적으로 필요하다.
- GenerationType.AUTO
즉, BaseEntity를 abstract 클래스(추상 클래스) 로 선언한 이유는 @MappedSuperclass 어노테이션을 사용했기 때문인데, 해당 어노테이션이 부여된 클래스는 Entity가 아니기에 조회, 검색이 불가능하다. 다시말하면, 직접 생성해서 사용할 일이 없기에 추상 클래스로 만드는 것이 방어코드 차원에서 권장된다.
또한 해당 프로젝트의 DB는 H2 이고, 기본키의 경우 우리가 직접 넣어주는 것이 아닌, DB에 위임하여 자동으로 AUTO_INCREMENT 하게 기본키를 생성해주기 위해서 @GeneratedValue(strategy = GenerationType.IDENTITY) 를 작성해준 것이다.
Owners
Entity
package kr.co.jshpetclinicstudy.persistence.entity;
import jakarta.persistence.*;
import lombok.Builder;
import lombok.Getter;
import lombok.NoArgsConstructor;
@Entity
@AttributeOverride(name = "id", column = @Column(name = "owners_id", length = 4))
@Getter
@NoArgsConstructor
public class Owners extends BaseEntity {
@Column(name = "first_name", length = 30)
private String firstName;
@Column(name = "last_name", length = 30)
private String lastName;
@Column(name = "address")
private String address;
@Column(name = "city", length = 80)
private String city;
@Column(name = "telephone", length = 20)
private String telephone;
@Builder
public Owners(String firstName,
String lastName,
String address,
String city,
String telephone) {
this.firstName = firstName;
this.lastName = lastName;
this.address = address;
this.city = city;
this.telephone = telephone;
}
}
@AttributeOverride
- @MappedSuperclass를 통해 상속받은 id 값을 재정의 해주기 위해 Override 해주는 어노테이션이다.
- DB의 Table에 id의 속성명을 각 'Entity명_id' 로 정의해주기 위해서 @Column 어노테이션을 사용하여 재정의.
@NoArgsConstructor
- 해당 어노테이션은 파라미터가 없는 기본 생성자를 생성
- @AllArgsConstructor 는 모든 필드 값을 파라미터로 받는 생성자 생성
- @RequiredArgsConstructor 는 final, @NotNull 인 필드 값만 파라마티로 받는 생성자 생성
@Builder
- 생성자가 아닌 방법으로 객체를 생성하는 방법
- Builder Pattern 을 사용하는 이유는 다음과 같다.
- 생성자를 사용할 경우, 만약 파라미터가 많아지게 되면 가독성이 떨어지게 된다.
- 생성자를 사용하여 생성시에도 파라미터의 순서때문에 오류가 날 수 있다.
- 이러한 문제들을 빌더 패턴을 사용하면 해결이가능하다.
즉, Owners Entity는 우선 id 값을 추가해주기 위해서 BaseEntity를 상속받았다. 해당 id 값을 테이블에 저장할 때 'entity명_id'로 저장해주기 위해서 @AttributeOverride 어노테이션을 사용하여 재정의 해주었다.
@Getter를 사용하여 모든 필드의 get메소드를 사용할 수 있게 해주었고, 각 필드들은 @Column 을 사용하여 DB 테이블에 저장될 이름과 길이를 정의 해주었다. 또한 @NoArgsConstructor 를 사용하여 파라미터가 없는 기본 생성자를 생성하도록 했다.
@Builder를 사용하여 firstName, lastName, address, city, telephone 을 파라미터로 받아 객체를 생성할 수 있도록 선언해주었고, 해당 코드를 파라미터별로 줄 바꿈하여 작성해준 이유는 Clean Code를 위해 이렇게 작성해준 것이다.
Builder 패턴의 사용이유는 하단의 글에 정리해놓았다.
[개념] 빌더-패턴(Builder-Pattern) 은 왜 사용해야 하는가?
[개념] 빌더-패턴(Builder-Pattern) 은 왜 사용해야 하는가?
스터디를 진행하며, 사용한 코드에 대해 설명을 하기 위해 공부를 하다보니 @Builder를 사용하는 이유를 제대로 알지 못해서 찾아서 공부를 하게 되었다. 객체를 생성해주기 위해서는 생성자 패턴
soohykeee.tistory.com
Repository
package kr.co.jshpetclinicstudy.persistence.repository;
import kr.co.jshpetclinicstudy.persistence.entity.Owners;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.stereotype.Repository;
@Repository
public interface OwnersRepository extends JpaRepository<Owners, Long> {
}
JpaRepository Interface
- JpaRepository<Entity 명, 해당 Entity의 id 타입>
- 해당 인터페이스를 상속하는 것만으로 Entity 하나에 대해서 아래와 같은 기능을 제공하게 된다.
- save() : 레코드 저장
- findOne() : PK로 레코드 찾기
- findAll() : 전체 레코드 가져오기, 정렬이나 페이징 가능
- count() : 레코드 개수 가져오기
- delete() : 레코드 삭제
- findBy~~로 시작하는 메서드
- countBy~~ 로 시작하는 메서드
우선 기능 개발은 하지 않고, 초기 설정과 의존성 주입만 하기로 했기에 위처럼 코드를 작성해주었다. @Repository 를 적어주어 스프링 빈으로 등록되도록 해주었고, JpaRepository 인터페이스를 상속받아주었다.
Service
package kr.co.jshpetclinicstudy.service;
import kr.co.jshpetclinicstudy.persistence.repository.OwnersRepository;
import lombok.RequiredArgsConstructor;
import org.springframework.stereotype.Service;
@Service
@RequiredArgsConstructor
public class OwnersService {
private final OwnersRepository ownersRepository;
}
@Service 를 작성해주어 스프링 빈으로 등록되도록 해주었고, 앞서 설명했듯이 @RequiredArgsConstructor 는 final이나 @NotNull 이 붙은 필드만 파라미터로 받는 생성자를 만들어주는데, 해당 어노테이션으로 인해 OwnersRepository 를 파라미터로 받는 생성자가 만들어진다.
Controller
package kr.co.jshpetclinicstudy.controller;
import kr.co.jshpetclinicstudy.service.OwnersService;
import lombok.RequiredArgsConstructor;
import org.springframework.stereotype.Controller;
@Controller
@RequiredArgsConstructor
public class OwnersController {
private final OwnersService ownersService;
}
위와 마찬가지이다.
Pets
Entity
package kr.co.jshpetclinicstudy.persistence.entity;
import jakarta.persistence.*;
import lombok.Builder;
import lombok.Getter;
import lombok.NoArgsConstructor;
import java.time.LocalDateTime;
@Entity
@AttributeOverride(name = "id", column = @Column(name = "pets_id", length = 4))
@NoArgsConstructor
@Getter
public class Pets extends BaseEntity{
@Column(name = "name", length = 30)
private String name;
@Column(name = "birth_date")
private LocalDateTime birth_date;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "owners_id")
private Owners owners;
@Enumerated(EnumType.STRING)
@Column(name="pets_types")
private Types types;
@Builder
public Pets(String name,
LocalDateTime birth_date,
Owners owners,
Types types) {
this.name = name;
this.birth_date = birth_date;
this.owners = owners;
this.types = types;
}
}
@ManyToOne
- 1:N에서 N(many) 쪽이 주인이라고 생각하면 된다.
- fetch = FetchType.LAZY / FetchType.EAGER
- FetchType.EAGER
: 즉시 로딩에 해당하는 부분으로, 해당 기능으로 엔티티 조회 시 연관관계에 있는 데이터까지 한번에 모두 조회하게 된다. 그렇기에 필요 이상으로 모든 엔티티를 조회하기에 성능이 조회될 수 있고, 이는 성능 저하를 야기할 수 있다. - FetchType.LAZY
: 지연 로딩에 해당하는 부분으로, 앞서 즉시 로딩과 다르게 필요한 엔티티만을 조회한다. 만약 연관관계를 참조할 때가 있다면 엔티티 조회 시에 SQL이 질의 되는 것이 아닌, 참조 시에 SQL이 실행된다.
즉, 즉시 로딩과 다르게, 연관관계까 있다고 하더라도 직접적으로 연관관계에 있는 것을 요청하지 않으면 불필요하게 모든 연관관계 테이블을 조회하는 쿼리를 날리지 않는다.
- FetchType.EAGER
@JoinColumn
- Entity 연관관계나 Collection 연관관계에서 Join 대상이 되는 Column을 나타낸다.
- 만약 해당 컬럼을 생략하게 된다면 '필드명_[참조하는 테이블의 기본 키 컬럼명]' 을 참조하게 된다.
@Enumerated
- Entity 클래스에 enum 타입을 사용할 때 작성해주는 어노테이션이다.
- EnumType.STRING / EnumType.ORDINAL
- EnumType.STRING
: 각 Enum 이름을 Column에 저장 - EnumType.ORDINAL
: 각 Enum 에 대응되는 순서를 Column에 저장
- EnumType.STRING
해당 Pets Entity는 앞서 Owners Entity에서의 설명과 동일하지만 다른점이 있다면 1:N 연관관계를 넣어주어 @ManyToOne을 사용했다는 것과 Enum 클래스인 Type 을 가져와서 @Enumerated 를 사용해주었다는 점이 있습니다.
기존의 테이블 설계를 보게되면 주인은 여러마리의 반려동물을 가질 수 있기에, Owners (주인)와 Pets (반려동물) 은 1:N의 관계를 가지게 됩니다. @ManyToOne 어노테이션은 N인 다쪽에 작성해주기에 Pets 엔티티에 해당 어노테이션을 추가해주었다. 해당 owners 와 join 대상이 되는 column 은 Owners Entity 의 PK 값인 owners_id 이기에 해당 값을 작성해주었다.
또한 Enum 타입으로 생성해준 Types 클래스를 사용해주기 위해서 @Enumerated 를 사용해주고, 반려동물의 타입을 ORDINAL을 사용하여 번호로 구분하게 되면 가독성에 문제가 생길 수 있기에, 보기 쉽게 STRING을 사용해서 타입을 직접 저장할 수 있도록 해주었다.